Monte Carlo Methods for the Game KingdominoDRAFT
The paper Monte Carlo Methods for the Game Kingdomino by Magnus Gedda, Mikael Z. Lagerkvist (me) and Martin Butler is presented at the IEEE Conference on Computational Intelligence and Games 2018 (CIG2018). This post summarizes our paper and gives some context on it.
Most of the work of researching, implementing, and writing was done by Magnus, so this post is mostly due to his work.
A pre-print version of the paper is available at arXiv and also on my research page.
Why study Kingdomino?
While the paper describes the board game and experiments in implementing Monte Carlo methods for it, we did not start with the intent of writing the paper.
Our interest in the game started when Martin bought a copy of the game at Spiel in Essen in 2016 when it was launched. We often played the game during lunch at work, and eventually even bought a work-place copy. Martin coded a game server for writing game playing agents, which we used at a one day hackathon implementing agents and competing. Both Magnus and I got very interested, and continued implementing our agents and discussing strategies and game playing in general. Eventually we had learned enough that we thought it worth writing a paper that summarized our findings.
Kingdomino
From the title it is easy to see that it is about playing the game Kingdomino, so let’s start by explaining the game and why it is interesting.

Kingdomino by Bruno Cathala won Spiel des Jahres 2017. It is a territory building game that uses an interesting card drafting mechanic and tile placement inspired by dominoes. The game has easy rules, is not overly competitive, great artwork by Cyril Bouquet, and is quite fast to play. All this makes the game very easy to explain and play with new people, while still having enough interesting game play to keep playing.
The aim of each player in Kingdomino is to expand their kingdom by consecutively placing dominoes provided in a semi-stochastic manner. A domino contains two tiles, each representing a terrain type and can have up to three crowns contributing to the score for its area. The goal is to place the dominoes in a 5x5 grid with large areas connecting terrains of the same type (using 4-connectivity) containing many crowns to score points. The score for an area is the number of tiles it consists of times the number of crowns in it. Note that this means that an area without crowns gets 0 points.
The two central mechanics are card-drafting and placement of dominoes in ones own kingdom. In each turn (except the first and last which are special) there is a previous draft of dominoes with markers for the players on their chosen dominoes and a current draft with new dominoes. Each player in turn according to the order of dominoes takes their chosen domino from the previous draft and places it in their Kingdom (if possible) and then chooses their next domino from the current draft. When all players have done this 4 new dominoes are drafted.
After all 48 dominoes have been played the game ends, and the player with the most points wins.
Kingdomino as a mathematical game
Kingdomino has some interesting properties as a game that is fairly unusual in game playing research. In particular, it is
- Multi-player
- Non-deterministic
- Limited fixed game tree depth
- High branching factor
- Somewhat limited interaction between players
Let’s go through the above properties in some more detail.
Multi-player game
Kingdomino is a game for between 2 and 4 players, and in the paper we focus on the 4-player version which is the more interesting to play. This is in contrast to the more common case in game theory where 2-player games are studied, such as Go, Chess, Backgammon, Connect-4, Othello/Reversi, and so on.
Non-deterministic
The game is non-deterministic since part of the game set-up is to shuffle the 48 domino tiles used (alternatively, dominoes are blindly drafted from a bag). This introduces additional complexity in implementing efficient algorithms for playing Kingdomino. In particular, it greatly increases the branching factor for the game.
Limited fixed game tree depth
A Kingdomino game has exactly 13 plies (a ply is a single move by a player) per player, for a total of 52 plies. This can be contrasted with an average of 70 plies for Chess and Checkers (35 per player) or the staggering 150 plies in Go.
High branching factor
A standard move in Kingdomino is comprised of two parts: placing the selected domino and choosing the next domino. From our experiments, we could see that the branching factor from this reaches as high as 60 with an average of around 30 in the middle of the game. While a large enough branching factor, it is slightly less than Chess for example.
The fact that a non-deterministic draft is used increases the the effective branching factor during the game tree search when a new draft is made to be up to 10 000 000 at the top of the tree and averaging at around 10 000 in the middle of the game.
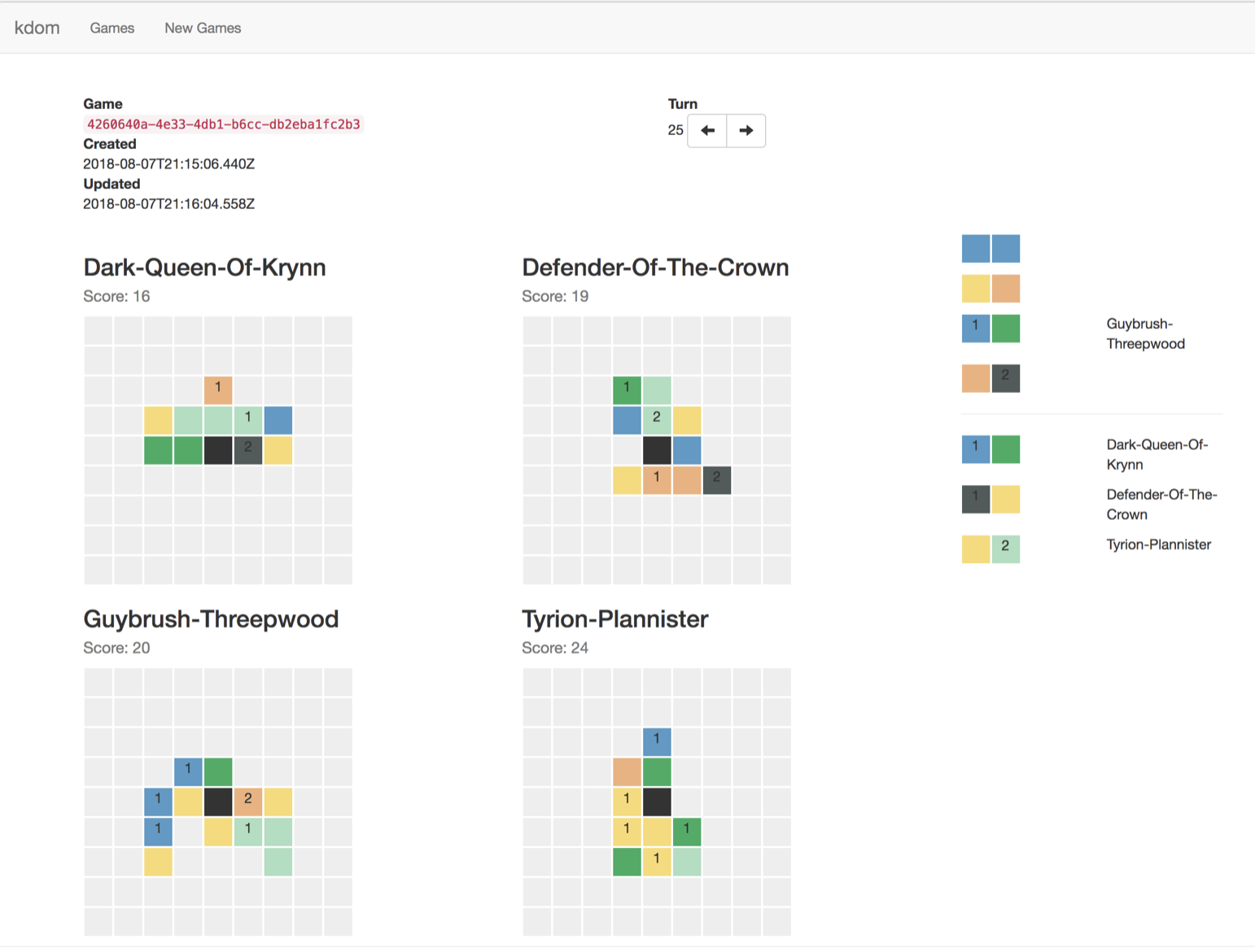
The Game Server
The Game Server
The game server uses a REST style Json protocol for agents to register as players and make moves in their current games. When making a move, an agent receives a Json object that contains all the visible information as well as a full list of all the possible moves. Since all communication is done using HTTP, agents can be implemented in any language.
The fact that all possible moves are provided makes it possible to write simple AI agents that use heuristics to guide their choice. At the hackathon this was a crucial aspect enabling all participants to write agents that could play in some reasonable manner. Worth noting is that the agents implemented that day were done in Java, Scala, Rust, Haskell, and Python.
The server is written in Scala and is packaged using Docker. It has an Angular-based front-end that shows the current and previous games, including stepping through all the plies in a game.
Notes on game state implementation
The game players used in the paper are all implemented in Java, mainly by Magnus. The agents are not implemented to be the most efficient possible, but some care has been taken to make them reasonably efficient.
In particular, quite some thought was given to the game state representation. My own implementation uses Rust as the language, and the game state is quite small (a couple of hundred bytes) and uses contiguous memory. A straight-forward Java implementation using objects and references quickly becomes quite large and spread out in memory.
Comparing playouts per second for the two implementations showed a large difference. Magnus implemented a new more low-level game-state using primitive byte arrays inspired by the Rust version, which improved the speed significantly.
Implementing Kingdomino strategies
The first step in implementing a strategy for Kingdomino is to evaluate the current state. Calculating the score is done by finding all 4-connected areas and summing their individual scores.
In each standard move, the player places the chosen domino from the previous draft and chooses a new domino among the available in the current draft. A simple solution is to place the domino greedily, choosing a placement for the domino that does not introduce any non-fillable areas such as empty single tiles. However, even better is to also take the choice of the next domino into account, and where that domino can be placed combined with the current domino. This is more expensive, but gives significantly better results.
To make strategic choices instead of only tactical choices, game tree search is needed. Given the very large branching factor, classical Minimax based strategies would be very expensive to run. Instead, we evaluate both flat Monte Carlo Evaluation (MCE) and Monte Carlo Tree Search (MCTS) using the UCT node selection algorithm. The basic idea behind Monte Carlo game tree search is to evaluate nodes by making randomized playouts from that node. MCE expands the game tree one level, and then makes playouts from those nodes collecting statistics. MCTS incrementally grows the tree while making playouts, choosing the next node intelligently.
We tested many variants of the basic strategies, and playouts using random moves, simple greedy moves, and the full greedy moves. We also tested a variant where the moves by the current player are done greedily, but the moves of all the opponents are simulated with random moves.
Our recommendations
Our initial assumption when implementing the agents had been that we would see an improvement from various greedy players to those that use Monte Carlo evaluation to full Monte Carlo Tree Search using the UCT node selection strategy. However, we saw that the MCE strategies seemed to be significantly better than the MCTS strategies.
To fully test the observed behavior, we performed a lot of experiments. The final evaluation ran more than 32 000 games with varying combinations of agents and varying time allotments.
Our main metric of comparison is the relative score for the player against the best opponent. For almost all time allotments, MCE using either full greedy playouts for all players or only for the current player was the best choice.
This result surprised us a lot, and we hope that it might be interesting for other games with similar characteristics. Importantly, MCE is much easier to implement than MCTS, which makes our recommendation even more appealing.
Is Kingdomino AI “solved” now?
Naturally, we could not test everything; there are a lot of ideas and possibilities that we did not have time to explore.
For the game tree search, improvements to our MCTS using relative scoring instead of Win-Draw-Loss scoring would be interesting. Also, limiting the node expansions to combat the stochastic nature of the game could be promising.
Another interesting avenue would be to evaluate if more structured (human-like) placement of dominoes could be used. Human players tend to follow specific strategies for placing their dominoes that might be useful for guiding the heuristics.